Multi-agent AI systems. Shipped to production.
I architect and ship custom agentic AI products for operations-heavy teams. Multi-agent orchestration. Eval-set rigor. Live in weeks, not quarters.
Built on agentic primitives
Capabilities
What I actually do.And how I do it.
Five things I'm hired for. Each one shipped to production at least once — most of them to the same customer.
Multi-agent orchestration
Coordinator, reviewer, and chat-as-orchestrator patterns built for the job — not pre-baked LangChain templates. Tool-use APIs, structured outputs, and stateful sub-agents that actually compose.
- Custom orchestration code, no template scaffolding
- Coordinator → workers → reviewer quality gate
- Chat-as-orchestrator for steerable pipelines
- Stateful sub-agents with shared memory
Process
How I build production AI systems
From the first scoping call to a system your team can run without me. Same shape every engagement.
Diagnose
Map the highest-pain workflow on your team. Identify time cost, error rate, and AI feasibility. You walk away with a written audit and a reference architecture — whether or not we work together.
- Workflow audit document
- Reference architecture sketch
- Eval criteria + success metrics
- Fixed-fee proposal (if there's a fit)
Every system ships with eval sets, monitoring, and a runbook. No black boxes.
The actual stack — production code, not no-code glue
Clients
Companies I'm building with.
Selective engagements. Each build phase-gated and shipped to production.
Featured Work
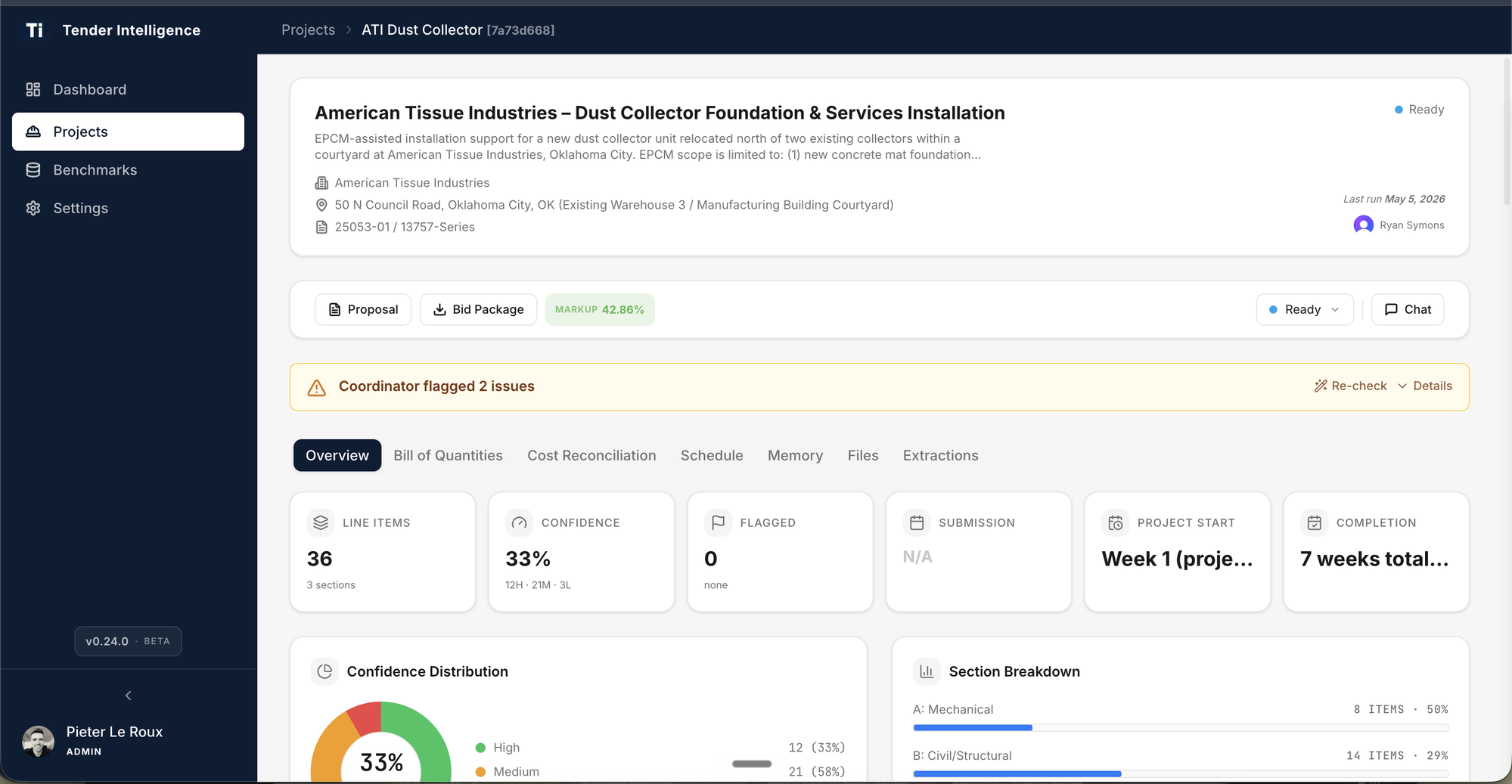
Tender Intelligence.An RFQ pipeline, in production.
A multi-agent AI product I built for an industrial engineering firm. Live in beta. The case study for everything else on this page.
From a 3-day RFQ cycle to a priced, scheduled, client-ready proposal in under 4 hours.
Drop a tender package — PDFs, Word docs, engineering drawings — into the system. Five specialised Claude agents extract the BOQ, suggest pricing against past wins, build the man-hour schedule, run a top-down sanity check, and produce a Word-ready proposal. Every number is editable, every artifact is auditable, and the system learns from each won project.
Reads tender PDFs, Word, and engineering drawings. Pulls structured BOQ items and specs.
Suggests pricing per line item from historical wins. Benchmarks against the firm’s actuals.
Builds editable man-hour and plant-hour schedules. Reconciles back to the BOQ.
Independent sanity-check on the bottom-up build. Flags variance against past projects.
Cross-checks every artifact. Reviewer is the draft→ready quality gate.
Estimator talks to the system; chat invokes regenerate tools. No deep-menu hunting.
Tender Intelligence is built by Accenzio for an industrial engineering firm. Metrics measured against the firm's pre-system baselines on real RFQ packages. Confidence figure refers to BOQ extraction with engineering drawings.
Engagements
Three ways to work together.Fixed scope. Fixed price. Code you own.
Milestone-gated payments and a written scope you can read in fifteen minutes. Pick the engagement that fits — stop at any phase.
Discovery & Audit
A senior-engineer-grade read on whether AI is the right tool — before you commit a build budget.
- Diagnosis call + workflow walkthrough (Loom)
- Written audit: time cost, error rate, AI feasibility
- Reference architecture (agent graph + stack)
- Eval criteria + success metrics defined
- Fixed-fee proposal for the build, if there's a fit
Best for: Teams who want a senior-engineer-grade read on AI feasibility — and a credible plan to build it right.
Book a Discovery →Custom AI Product Build
A multi-agent system, custom code, shipped to production.
- Multi-agent architecture, custom code
- Anthropic Claude tool-use, structured outputs
- Eval sets + regression baselines from day one
- Production deploy, monitored end-to-end
- Sentry · structlog · runbook · full handoff docs
- Phase-gated billing — exit ramp after Spec
Best for: Teams with one painful, high-value workflow that needs a real product — not a Zapier patchwork.
Start with a Discovery →AI Ops Partner
Once the build is live: the system stays sharp, monitored, and improving.
- Eval-set regression checks on every release
- Sentry on-call, weekly ops brief
- Model + tool updates as the field moves
- Continuous improvement against measured baselines
- Standard tier absorbs new automation work
Best for: Teams whose system is in production and needs a senior engineer keeping it tuned.
Book a call →
About
You'll work with me. Not a project manager.
I'm Pieter — an AI systems architect with twenty years of engineering across the stack. Full-stack development, cloud infrastructure, security engineering, and the last several years deep on agentic AI in production. Accenzio is the studio I run for selective custom builds. Based in Austin. Available worldwide.
I build two things well: multi-agent systems that actually hold up in production and the eval-set discipline that proves they do. Everything ships with logs, monitoring, runbooks, and a handoff that means your team can run the system without me.
FAQ
Common questions.Honest answers.
The things buyers always ask before booking a call. Answered upfront.
Got a different question? Bring it to the diagnosis call.
Book a 15-min callGot a workflow that needs a real product behind it?
Free 15-minute diagnosis. No slide deck. We'll find the highest-ROI workflow on your team's plate and tell you, honestly, what it would take to ship the multi-agent system that solves it.